Forging the Algorithm
Here’s a lightly edited version with the same meaning:
Forging the Algorithm Arseniy
Backstory
In earlier posts I talked about my time at Equifax, where I encountered instability in credit-scoring models. I outlined the main ideas behind feature engineering and target construction for this task, and I wrote the largest PL/SQL script I’ve ever written.
Forging an Algorithm
After a while I joined HeadHunter. Things stabilized and the work began. Two or three times a week, after a full day at the office, I would travel from Alekseevskaya to Park Kultury in Moscow (about 45 minutes). There, my friend and I worked on gradient-boosted decision trees with extrapolation. We started by deriving the standard gradient-boosted decision-trees algorithm.
The core procedure is splitting. Let’s unpack it step by step. First, we need to choose a loss function to minimize. Suppose our model produces a score
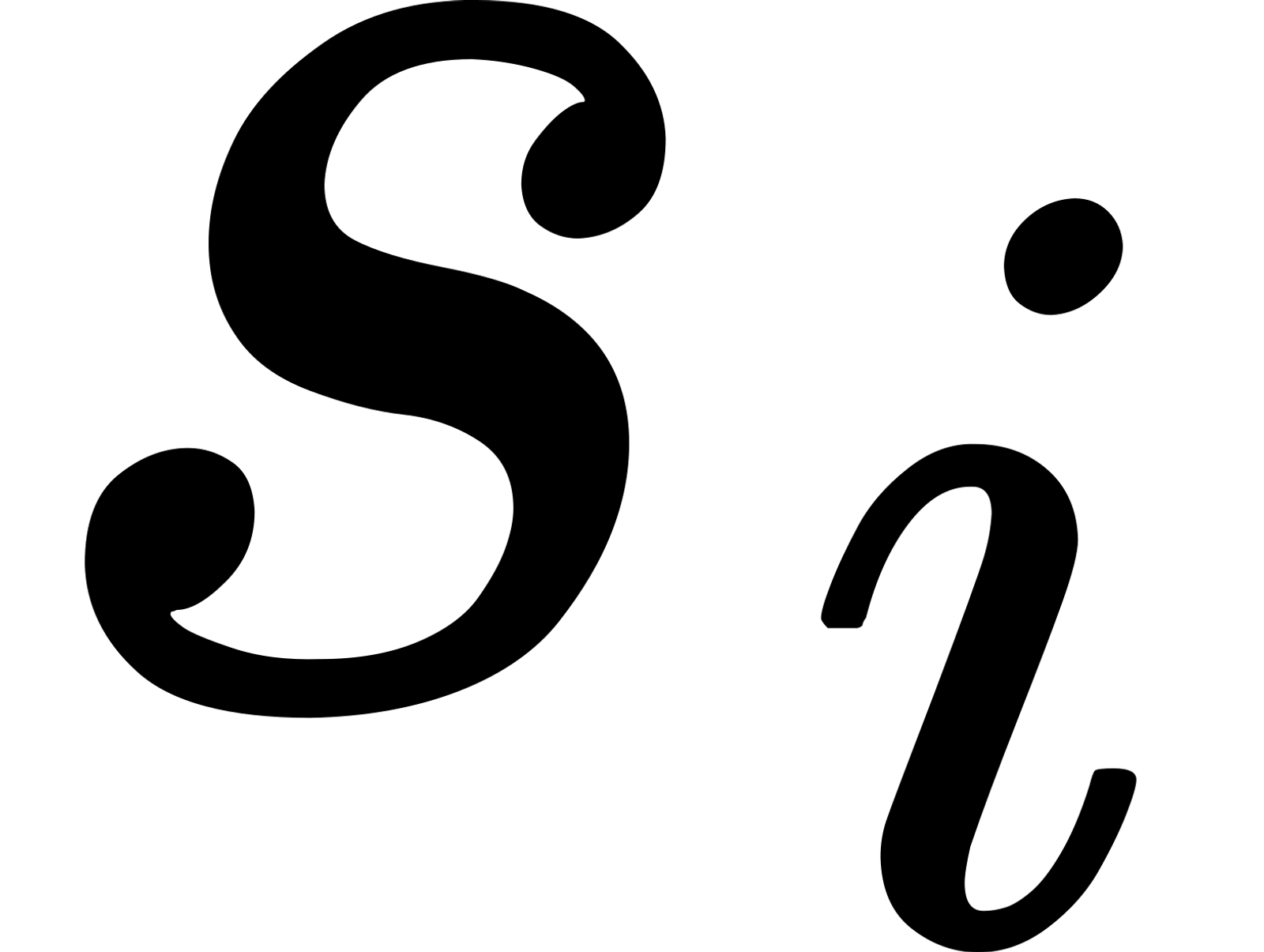
s_ifor object i whose true label is
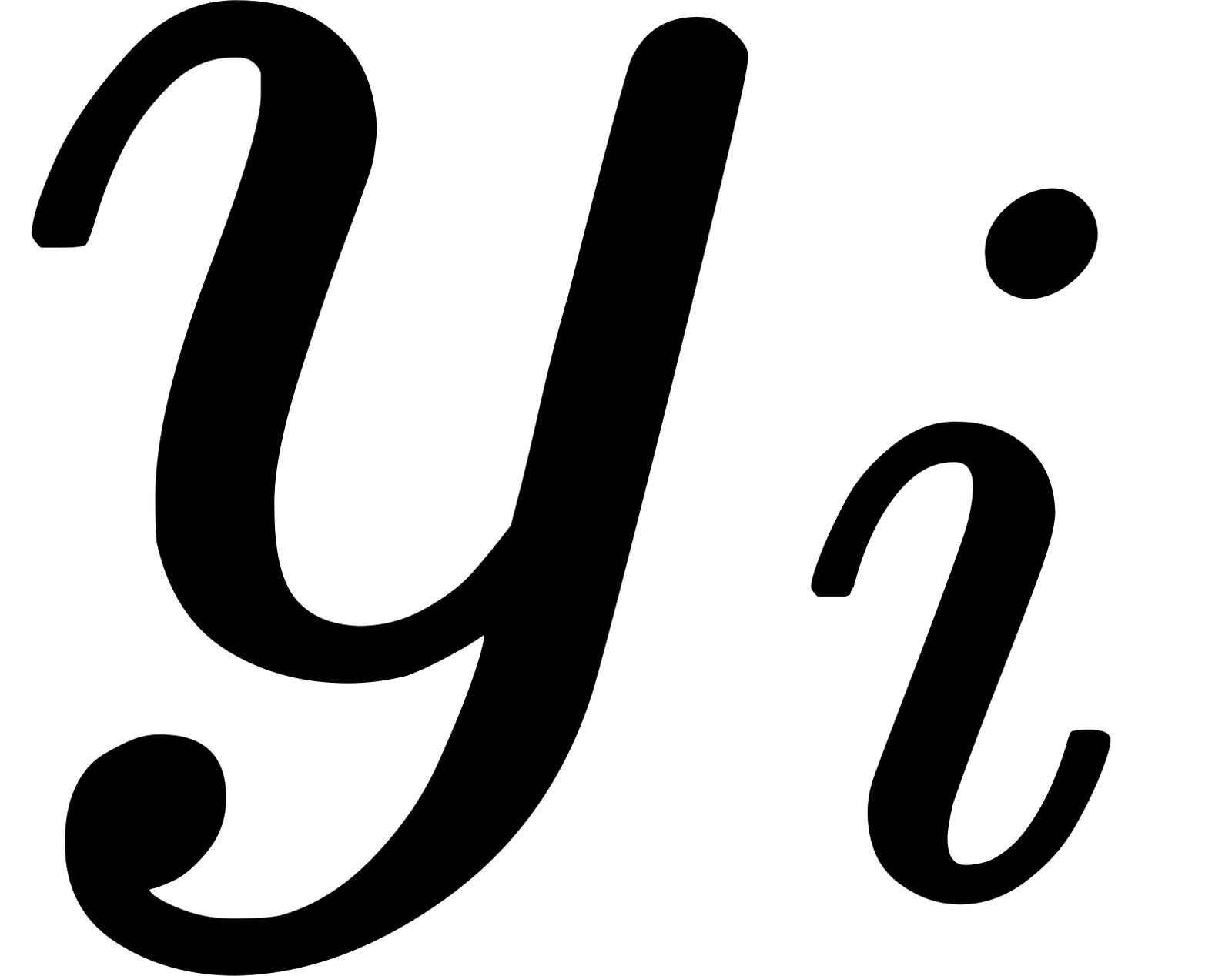
y_iThe loss for this object is l(s_i, y_i), and the total loss is: